.png)

A Structured Approach to Maintaining Your AI Agents Context Window
Why context engineering becomes durable only when you treat knowledge as infrastructure: sourced, structured, versioned, audited, and loaded into the model on purpose.
I have a folder on my machine called Knowledge. Inside it, an AI agent maintains a wiki of everything I've learned about my own work - sourced, cross-linked, version-logged, and audited weekly. My agents read it before they do anything.
Here's what most people haven't internalized yet: the model is a cheap, commoditized layer. The exponential return is the context it references.
Most people are still hand-feeding one conversation at a time and wondering why the same task produces sharp work on Tuesday and generic mush on Thursday.
Karpathy already named the discipline
Andrej Karpathy has argued for "context engineering" as "the delicate art and science of filling the context window with just the right information for the next step."
His mental model is the one to steal:
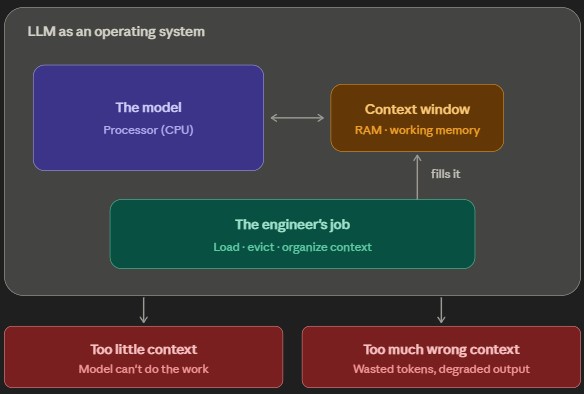
The LLM is a new kind of operating system. The model is the CPU. The context window is the RAM. The engineer's job: decide what to load, evict what's stale, and organize it so the processor runs well. Too little context and the model can't do the work. Too much wrong context and you waste tokens while degrading output quality.
What I actually built from Karpathy's model
The Knowledge folder is split into domain knowledge bases - AI Agents, Business Cases, Personal Brand, Productivity, Developing Skills, and RAG. Each one is a self-contained wiki with its own operating manual, written as a CLAUDE.md file the agent reads on entry. That file defines what the KB is for, the five themes it should go deep on, the page formats, and the rules for changing anything.
The agent that runs each KB uses an operating manual that gives it a role: active librarian. It ingests sources, writes and links pages, and flags gaps on its own - and it logs every change to an append-only CHANGELOG.md so I can audit everything. It pauses and asks before anything destructive: merging pages, renaming a concept, removing content.
Each KB follows the same shape.
A RAW/ folder holds source material - articles, transcripts, PDFs I've dropped in.
A Wiki/ folder is the librarian's domain: an index.md cataloging every page, an overview.md synthesizing the current state of what's known, and the pages themselves, sorted into principles, patterns, platforms, sources, and content angles.
An Outputs/ folder catches generated analyses, and the good ones get promoted back into the Wiki.
The workflow is three operations.
Ingest
I drop a source in RAW/ and say "ingest this." The agent reads it fully, finds the existing Wiki pages, updates them, creates a new page only if the idea is genuinely distinct, and records the whole thing in the changelog.
Query
It reads the index, pulls the relevant pages, and answers with citations to them.
Lint
It audits the KB for contradictions, orphaned pages, and claims with no source behind them.
Researching the frontier is the actual job
The hard part of working with AI right now isn't the tooling. It's that the field reinvents itself every few weeks, and most of it lives in a research paper, a GitHub repo's cookbook, a vendor's benchmark post, a town-hall transcript, or an MIT Sloan piece that frames a problem in a way you hadn't.
Read those once and you forget 90% of them. That's the leak.
So my RAW/ folders are where this all gets metabolized. MIT Sloan articles on adaptive governance and compounding returns. Anthropic town-hall notes on agent memory. Google agent docs. PageIndex research on vectorless retrieval, pulled straight from their blog and cookbooks. Each one gets ingested, interpreted, and reduced to a durable claim with the receipts attached - not bookmarked and lost.
This is the move I'd push on anyone serious about building. Read frontier material, interpret it, decide what's established versus hype, what applies to your work, what contradicts the thing you read last month, and then write that judgment down where your agents can reach it.
That's the compounding asset. The article you read is depreciating from the moment you close it. The interpreted, sourced page you wrote about it appreciates, because every future piece of work and every future source connects to it.
The frontier doesn't reward whoever reads the most. It rewards whoever retains and connects the most. A knowledge base is how you win that game instead of drowning in it.
It's not a lookup. It's reasoning over what I know.
Most people picture a knowledge base as a search box - embed everything, retrieve by similarity, paste the nearest chunks into the prompt. That's vector RAG, and one of my KBs exists specifically because that model breaks on the problems that matter most.
The core finding in my RAG wiki: semantic similarity is not the same as relevance. Vector search finds text that looks like your query. It misses the section that actually answers it.
The alternative is structured reasoning - what PageIndex calls an in-context index: a table-of-contents tree that lives inside the model's reasoning context, so the agent works through it the way an analyst flips through a binder. Read the structure, decide where the answer probably lives, go there, follow the cross-reference. My Knowledge folder is that, hand-built, for my whole practice.
The index.md and overview.md are the table of contents. The principles, patterns, and sources are the sections. When an agent works a problem, it reasons through a structured map of what I know and decides which principles apply.
What you get is consistency
Speed is the obvious win. It's real, but it's not the one that mattered.
Before the knowledge base, output quality depended on how much context I happened to load into that specific chat. Careful session, sharp work. Rushed session, mush I'd rewrite. Same model, same me - the difference was entirely what I remembered to type.
A documented workspace raises the floor. The worst thing an agent produces now is bounded by what's written down, not by my memory at 11pm. Two agents handed the same task land in the same place, because they're reading the same source of truth. You can't scale a practice whose quality swings with the operator's memory on a given day - this is what fixes that.
This is where workflows and skills come from
Here's the part that turns a knowledge base from a reference into an engine.
A principle, once it's sourced and stable, is a spec. "Agent Quality Is an Architecture Problem" isn't just a thing I believe - it's the design doc for a skill I built that audits an agent's scope, tool permissions, and escalation rules before it goes live. The principle defined what the skill checks. The wiki page is upstream of the workflow.
That's the pattern. The knowledge base accumulates interpreted frontier research; the stable principles harden into repeatable skills; the skills get reused across clients and projects. When I design a new workflow, I'm starting from a set of audited principles that already encode what works, where it breaks, and what the sources say.
I automated the part teams always skip
Documentation rots. Everyone who's maintained a team wiki knows the failure mode: it's pristine for a month, then someone changes how things work and nobody updates the page, and six months later half of it is quietly wrong. A knowledge base that lies is worse than none.
So the maintenance runs on a schedule. Once a week, an automated task works through every KB and runs seven audits: contradictions between pages, claims with no source behind them, gaps where a referenced concept was never actually written up, broken cross-links and orphaned pages, stale articles, format violations, and connections that should exist but don't. For factual gaps the open web can fill, it runs a search and proposes the answer with a URL.
It's deliberately report-only. It never edits a page on its own - it writes a findings report and proposes fixes, and I approve them. The maintenance burden of keeping documentation honest, the exact thing that kills most wikis, is the part I handed to a machine. The judgment stays with me.
Why this matters more in regulated work
I lead AI product strategy in healthcare, and there the documentation discipline isn't a nice-to-have - it's the requirement. When an AI system touches anything sensitive, "it usually does the right thing" is not an acceptable standard. You need to know why it did what it did, that it'll do the same thing tomorrow, and that the reasoning sits somewhere a human can audit.
A sourced, version-logged knowledge base is what makes that defensible. Every position an agent takes traces back to a page you can point at, a source you can check, and a changelog showing when it changed and why. When a rule changes, you change the page, and every agent reading it updates at once. That's governance you can stand behind, instead of hoping each operator remembered the current policy.
The regulated setting just makes the requirement loud. It's true everywhere. Undocumented AI behavior becomes a liability the moment more than one person, or more than one agent, depends on it being consistent.
How to start without boiling the ocean
Start with the thing you re-explain most. For me it was voice - I was pasting the same writing rules into every session, so those rules became the first page. Write down the context you're tired of repeating, point an agent at it, and watch what it gets wrong. The gaps tell you the next page to write.
Keep pages small and single-purpose. One claim, one source, one status. Big documents rot because nobody updates them and the agent wades through noise to find the part that matters.
Hand the upkeep to an agent and keep approval for yourself. Documentation rots when the maintainer is "me, when I remember." Mine runs a weekly check that flags contradictions, stale pages, broken links, and claims with no source behind them - then proposes fixes I approve.
And feed it the frontier. The field reinvents itself every few weeks. Ingesting knowledge to this system is how reading turns into an asset.
The honest takeaway
The shift is small but large in effect: stop treating context as something you supply per conversation, and start treating it as an asset you build once, maintain on a schedule, and reason over forever.
Karpathy named the discipline. The knowledge base is how you actually practice it - the durable store that pages the right context into the model's working memory, run after run, instead of you doing it by hand and forgetting half of it. The models will keep getting better on their own; that's Anthropic's job and OpenAI's job, not yours. Your edge is the context only you have assembled, interpreted, and kept honest. That edge compounds.
The people who win the next phase won't be the ones with the best prompts or even the best models - everyone gets the same frontier models within weeks of each other. They'll be the ones who built the disk: a structured, sourced, self-auditing base of everything they've learned, wired so their agents reason over it before they act.
I'm adding to mine constantly. Every time I catch myself re-explaining something, that's a page I should have written. Start yours today. Find the thing you keep repeating, write it down, point an agent at it, and don't stop.
What context are you still hand-feeding your agents every single session?